





万圣节前夜,硅谷把“AI能替人类打工”的幻想拖进现实揍了一顿。
Scale AI让GPT-5、Claude、Gemini等一批“学霸”模型去“打零工”。不是做选择题,也不是写论文,而是独立登录自由职业平台接真实订单。客户付真钱,模型交真货。
这场测试被命名为“远程劳动指数”,是全球首个专门衡量AI“能否真正干活”的基准。
实验结果像一场职场闹剧:每个模型有忙前忙后,表现最好的那个,240个工单也只完成了6个,赚到1720美元,还不到人类自由职业者报酬均值的2%。
近一半的失败原因是,质量太差、成品业余。
在“分数上天、交付落地”的AI时代,这是一次令人尴尬的对照实验。尽管大模型在标准测试中表现惊人,但将这种“智力”转化为现实世界中的“经济价值”的能力还非常初级。
它也提出了一个比“AI是否聪明”更现实的问题,当真正要为结果付钱时,人们到底愿不愿意雇用AI?目前来看,人机协作仍然是短期到中期的唯一路径。
01
让大模型去赚外快,仅2.5%成功率
AI到底能不能自己帮我赚外快?
Scale AI的前CEO Alexandr Wang最近带头搞了场“AI打工实录”,给出这样的答案:极少数、且限制重重。
为了搞清楚这件事,Scale AI搞了个叫“远程劳动指数”(RLI)的新标准,直接把各大模型当成“打工人”扔进真实项目里接单。
评判标准很现实:客户肯不肯付钱,平台认不认为这活儿干得专业。
他们特意选了自由职业项目来测试,因为这类任务独立、完整、还带真实报酬,最能看出AI到底有没有“独自上班”的能力。
测试范围不包括需要持续沟通、团队合作或线下动手的活儿,主要覆盖写作、3D建模、视频动画、建筑设计、游戏开发等23类常见线上工作。
RLI的设计核心就俩字:真实。
所有测试项目都来自全球最大自由职业平台Upwork上的真实订单,一共240个,加起来相当于人类6000小时的工作量,总报酬高达14.4万美元。
每个任务都配备了完整的需求说明、相关素材和人类交付样例。比如,做数据报告任务,要求AI根据《世界幸福报告》的Excel数据,做出带世界地图和分数拆分的交互式报告。

▲交付要求示例
整个流程高度仿真:从理解需求、下载文件、多轮修改到最终提交,任何一个环节掉链子都算任务失败。
结果嘛,有点惨烈。所有参与测试的AI模型,对复杂项目的整体自动化率,都低于3%。
表现最好的Manus,成功率也只有2.5%,也就是240个任务里只完成了6个。换算成报酬,它只赚到了1720美元,而人类完成所有这些任务可以赚到14.4万美元。
其他“学霸”模型更拉胯:Grok 4和Claude Sonnet 4.5稍逊于第一名,均为2.1%;GPT-5为1.7%;ChatGPT Agent为1.3%;而Gemini 2.5 Pro垫底,只有0.8%。
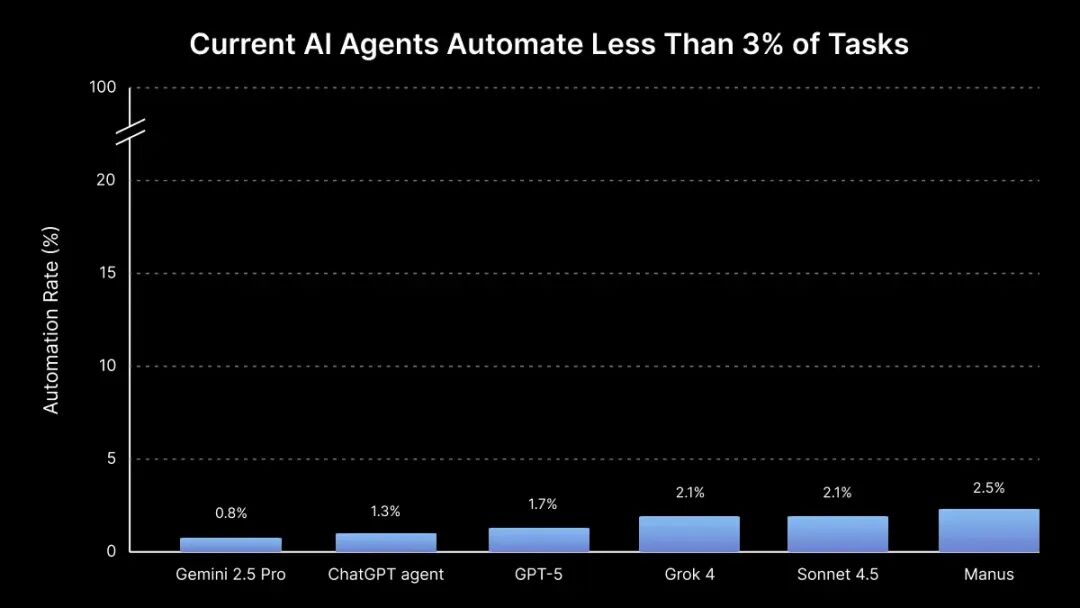
▲AI的任务通过率统统不超过3%
目前来看,指望AI完全自主干活,效率实在有点低。研究团队发现,AI的失败不是随机的,主要集中在这四类情况,且一个任务能踩好几个坑:
①45.6%的任务“质量过低”,成品显业余,达不到专业标准;
②35.7%的任务“不完整或格式错误”,如视频被截断、文件缺失;
③17.6%的任务“技术与文件完整性问题”,如损坏、编码错误;
④14.8%的任务“严重的视觉或逻辑不一致”,例如多镜头视角对不上、文件间彼此矛盾。
典型案例如:在一个珠宝设计项目中,AI的任务是“修改提供的戒指图像,改变钻石切工”。结果它完全无视客户提供的原图,自己放飞生成了两张全新的AI图,图片质量业余、没按需求来、两张新图还对不上,一口气触发了三种失败模式。
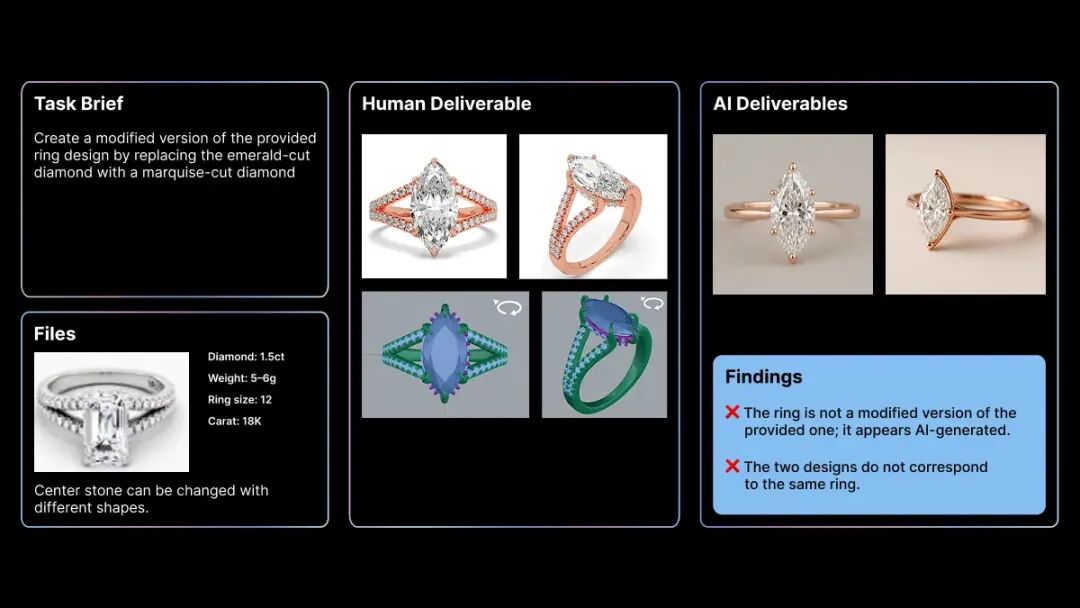
▲AI被“退货”的典型案例
失败原因指向更深的系统性问题。
“质量低下”说明AI根本不懂什么叫“专业标准”;“不完整/格式错误”则暴露了它在处理多步骤、多工具工作流时有多么脆弱。
不过AI也不是一无是处,它在某些特定类型任务上还是有点天赋的,主要集中在两类:一是创意类任务,比如制作音效、设计Logo;二是基础内容类任务,比如部分数据整理或写作。
简单来说,AI擅长“从零开始搞创作”,生成能力不错。可一旦任务需要它串起多个工具、执行多步骤操作、保持文件间的一致性,或者在别人成果上做二次编辑,它基本就手忙脚乱,集体翻车。
虽然AI出活速度快,但交付质量实在难以达标。人类完成一个项目平均要28.9小时,而AI投入相近的“算力时间”后,大部分成果还是被判定为“不合格”。
这其实说明了一个趋势:工作正在被“拆解”,而不是直接被“替代”。
在RLI中,任务被分为L1到L5五个难度等级。像资料整理、基础文案这类L1-L2任务,AI通过率能达到25%-30%;而涉及跨工具协作、创意策划的L4-L5任务,通过率却低于5%。有意思的是,L1-L2任务正是很多人类初级岗位的日常。
按照“智能体摩尔定律”,有人预测到明年底,最强的AI智能体有望完成一半的远程工作任务。
研究团队也强调,AI的各项指标还在快速进步,RLI基准也会持续追踪。他们计划不断更新测试任务库,并加入多模态、长记忆、工具调用等新维度,目标很明确:把“模型能力”真正转化为“经济价值”来衡量。
02
旧基准失灵,“满分”模型变“掉链子同事”
AI正在考试中证明“聪明”,却在职场中暴露“不会干活”。
近两年,大模型在封闭题库中的分数飙升,GDP-eval、SWE-bench等评测接连被刷到满分。而另一边,企业的初级岗位招聘却在降温。AI的“考试成绩”与真实就业市场的表现,首次出现了明显背离。
原因很简单:现有基准测的是“答题能力”,而企业要的是“交付成果”。
微软CEO Satya Nadella曾公开吐槽:“我们自诩达到AGI里程碑,不过是基准测试作弊。”
这正是典型的“高分低能”。模型选择题全对,写代码却漏了import;推理论证严密,做方案却缺了关键信息。更严重的是,为了“刷榜”,不少模型训练时已将测试集“腌”进参数里,分数越高,离现实越远。
AI领域迫切需要一种能衡量“真实工作能力”的新标准。
Scale AI推出的RLI正是为此而生。它不考一题一答的知识点,而是考“能否完成一整个工作流”——就像现实职场那样,任务有上下文、要协作、要产出可交付成果。
那么,RLI和传统基准有何不同?
MMLU、MT-Bench和ARC Challenge都是当前评估大模型时“出场率”最高的主流基准之一,几乎所有新模型发布都会贴出这三项分数。不过,它们各自存在明显短板:
MMLU覆盖57学科,更像闭卷知识竞赛;
MT-Bench用两轮对话给分,只能反映“聊天体感”,无法衡量跨工具、跨步骤的复杂协作;
ARC Challenge聚焦抽象常识推理,与现实场景脱节。
相比之下,RLI用真实付费订单作为测试题目。模型不仅要理解任务、跨工具操作,还要交出客户愿意付钱的成果。这样的评测几乎无法“刷分”,它考验的是全流程适应力。
现实中,甲方突然要求改语气、换配图风格;客户上传的参考资料缺页、压缩包损坏;或任务中途新增“请在Notion里同步进度并生成演示稿”。这些人类面对的模糊又多变的现实,是模型能力测试中不曾出现过的。
正如AI安全研究员Dan Hendrycks所说:“没有什么比现实更复杂。AI的进步,必须以真实经济价值为衡量标准。”
那AI到底能不能独立上岗?
RLI实验结果显然说明“AI绝对自动化率几乎为零”,AI即将全面替代人类工作”的担忧暂时缺乏数据支撑。
短期内,市场还不会被“AI劳动力”淹没,但任务颗粒度变细、价格分层已在所难免。哈佛分析了500万家美国企业的招聘数据后得出,AI引入后,初级岗位招聘量平均下降7.7%,尤其集中在批发零售、行政支持等流程标准化行业。
未来的初级岗位JD可能会写成这样:“能使用AI完成30%的日常杂务,并具备确保交付的能力。”
AI的崛起正在重塑工作结构。纯执行型技能正在加速贬值,定义问题、管理流程、整合资源的能力,反而成了新的核心竞争力。
AI在考试中证明了“聪明”,而真正能在现实中“干活”的,依然是那些懂得如何让AI变成团队一部分的人。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。


